
【论文泛读】逃离依赖陷阱
原文
Escaping Dependency Hell: Finding Build Dependency Errors with the Unified Dependency Graph
0 摘要
在使用构建脚本来组装软件的可执行部件时,经常会出现依赖相关的错误,主要包括依赖缺失和依赖冗余这两类,这些错误可能会导致构建失败或者构建效果不佳。为了检测依赖错误,人们提出了许多技术,但由于底层依赖图的缺陷,这些方案的效率低下,并且检测结果的假阳性率高。本文提出一种基于统一依赖关系图(Unified Dependency Graph ,UDG)的遍历的方法来检测依赖错误,并且实现了工具VERIBUILD,进行了实验评估。实验结果表明,该方法不仅高效而且不会损失精度。
1 介绍
该部分首先介绍了构建系统(如GNU Make,GNU Autotools等)及相应的构建脚本在现代大型软件项目中的重要性,并引用了几个数据来说明构建错误的常见性。
接着引出依赖错误在构建错误中占最大部分,并归纳为两类:依赖缺失和依赖冗余。根据文中的描述和例子,依赖缺失指实际的依赖关系没有被声明;依赖冗余指声明的依赖关系实际上没有对应。
然后本文根据依赖关系图如何表示构建目标以及依赖关系,把检测依赖错误的技术分为三类:
第一类是基于构建脚本和执行的shell命令构建静态依赖关系图,显然这样的图里只能包含显式声明的依赖关系,而没有实际的依赖关系,因此不可能去检测依赖缺失和依赖冗余这两种错误,只能检测一些显式的错误,例如循环依赖问题。
第二类是通过监视和捕获构建过程中的实际依赖关系来构建动态依赖关系图,然而单纯的动态依赖关系图也只是包含实际依赖关系,而没有声明依赖关系与之相对比,所以也不能检测出依赖缺失和依赖冗余。更进一步,有人提出一种构建模糊技术 MKCHECK,它通过触发增量构建来推断构建脚本中的声明依赖关系。虽然这种方法能够结合比较实际依赖关系和声明依赖关系,但对于一个具有很多源文件和复杂依赖关系的大型项目来说,增量构建的方式太低效了。
第三类是利用静态和动态依赖关系图的交叉引用来发现声明依赖关系和实际依赖关系的不一致性,可以检测依赖缺失和依赖冗余。但这类方法也存在两个问题,一是传统的静态依赖图是不健全的,缺少隐式声明的依赖关系;二是现有工作中采用的静态和动态依赖关系图的粒度不同,很难弥补静态信息的不健全问题。
在以上前人工作的基础上,本文提出一种新的方法:构建一个统一的依赖关系图,对于每个构建目标,通过简单的图遍历,既能推断隐式声明的依赖关系,又计算在运行时发生的实际依赖关系,这两个遍历结果的差异意味着依赖关系潜在的不一致性。
2 预备工作
2.1 构建系统和脚本
这部分介绍了现代软件项目的构建流程:开发人员编写构建脚本(例如,Makefiles)来指示一个构建工具(例如,GNU Make、NMake、BuildCop)按照脚本中指定的顺序执行构建命令。然后通过一个例子,说明了增量构建和并行构建的异同点。
2.2 依赖缺失和依赖冗余
这部分通过定义和举例详细说明了依赖缺失和依赖冗余的概念和发生的情形,同时指出了对应产生的构建错误。
2.3 建立声明和实际的依赖关系
这部分主要描述了统一依赖关系图(Unified Dependency Graph ,UDG)的具体含义。以下是文中定义的一个UDG。
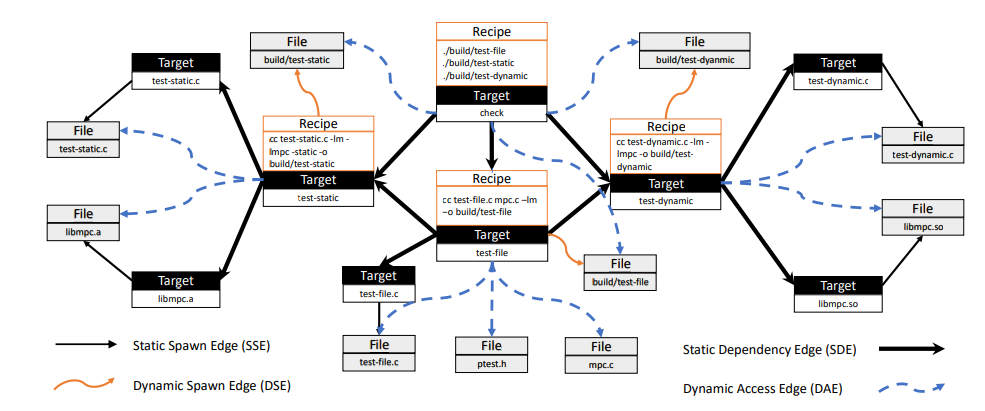
可以看出,UDG是一类有向无环图,图中包含四种有向边:静态生成边(Static Spawn Edge,SSE),静态依赖边(Static Dependency Edge,SDE),动态生成边(Dynamic Spawn Edge,DPE),动态访问边(Dynamic Access Edge,DAE)。
结合前文的例子,一条静态依赖边代表目标之间的依赖关系,而一条静态生成边表示构建目标被定义为一个文件的情况。这两类静态边构成的子图是传统的静态依赖关系图,在这个子图中,隐式声明的依赖关系可能会被静态解析构建脚本遗漏。
为了避免隐式解析的麻烦,作者利用构建工具去捕获每个构建目标的输出文件和输入文件,然后在图中引入了动态生成边和动态访问边 。一条动态生成边表示一个目标和它的一个输出文件之间的实际依赖关系,而一条动态访问边表示一个目标和它的一个输入文件之间的实际依赖关系。由这两类边组成的子图是一个动态依赖关系图。
2.4 检测依赖缺失和依赖冗余
在建立了UDG之后,检测依赖缺失(MDs)和依赖冗余(RDs)这两种常见的与依赖相关的构建错误,就可以转换为对UDG图的遍历。
以上图为例,要检测MD问题,对于构建目标测试文件的MD问题(缺少对ptest.h和mpc.c的声明依赖),首先从test-file开始,沿着静态依赖图的边进行遍历来发现测试文件所依赖的文件集,其中只包括test-file.c。然后沿着动态依赖关系图的边来发现test-file实际依赖的文件集,包括 test-file.c,ptest.h, 和 mpc.c。我们可以很容易地发现这两组文件之间的不一致。从而,ptest.h和mpc.c是test-file的缺失依赖项。
检测构建目标test-file的RD问题的过程是一个类似的过程。首先,寻找到测试文件的实际依赖文件包括 test-file.c, ptest.h, 和 mpc.c.。然后,为了验证test-static是否是testfile的一个冗余的声明依赖,从test-static开始遍历,以发现test-static所声明依赖的文件集,包括 test-static.c 和 libmpc.a,它们并不对应于 test-file 的实际依赖文件。因此根据RD问题的定义,test-static 是 test-file 的一个冗余的声明依赖。
3 方法
在本节中,首先正式定义UDG(第3.1节)。然后是详细描述了一个统一的UDG构造方法。该构建方法包括两个步骤:
解析和评估构建脚本,以推断出静态依赖图(第3.1.1节)。
构建工具,对构建过程进行工具化,以推断出实际的依赖关系(第3.1.2节)。
构建UDG后,检测MDs和RDs可以可以被建模为对UDG的图查询(第3.2节)。
最后,对该方法的可扩展性进行了讨论和证明(第3.3节)。
3.1 UDG 的定义和构造方法
定义
UDG = (V, E),V是点集,E是边集:
- $V=V_F\bigcup V_T$ ,$V_F$和$V_T$是两个不相交的子集,其中$V_F$是文件节点的集合,$V_F$是目标节点(代表构建脚本中的一个目标)的集合。
- $E=E{SD}\bigcup E{SS}\bigcup E{DA}\bigcup E{DS}$ ,$E$由四个不相交的子集组成,分别是静态依赖边集($E{SD}$)、静态生成边集($E{SS}$)、动态访问边集($E{DA}$)、动态生成边集($E{DS}$),这些子集分别包含满足一下条件的边:
- $e{SE}\in E{SE}\subseteq V_T\times V_T$
- $e{SS}\in E{SS}\subseteq V_T\times V_F$
- $e{DA}\in E{DA}\subseteq V_T\times V_F$
- $e{DS}\in E{DS}\subseteq V_T\times V_F$
构造方法
脚本解析
对于构建脚本中列出的每个目标,创建一个相应的节点。构建一个目标的命令被保存在在目标节点的recipe 中。对于构建脚本中指定的每个依赖性规则,创建从目标节点到其所有的依赖关系。对于每个有空recipe 的目标节点。检查它的默认输出文件(即与目标名称相同的文件)是否存在于文件系统中。如果输出文件存在,就创建一条从目标节点到文件节点的SS边代表这个文件。在脚本解析之后,所有的目标节点、SD边和SS边都被构造出来了。文件节点代表构建的输入(例如,源代码文件和配置)的文件节点也已被创建。结果图准确地描述了构建脚本中指定的静态依赖关系。
构建工具化
这个方法不监测构建的文件操作,而是执行一个构建工具,它启动每个目标的构建并分别捕获文件操作。
基于在脚本解析阶段获得的静态依赖关系图,按照该图的拓扑顺序,通过执行它们的recipe 来构建所有的目标。为每个recipe 的执行fork一个新的进程,并捕获由fork进程及其子进程执行的与文件相关的系统调用。
对于每个文件的读取操作,我们创建一个从目标节点到文件节点的DA边。对于每个文件的写入或创建操作,创建一个从目标节点到文件节点的DS边。在构建工具后,就得到了完整的UDG。
3.2 基于UDG的依赖分析
检测依赖缺失(MD)
为了检测一个目标的MD,首先分析它所声明的的依赖关系。算法1显示了两种查询程序可用的文件AvFnBefore和AvFnAfter,用于查询建立一个目标之前和之后的可用文件。在该算法中,𝑡 .𝑠𝑢𝑐𝑐𝑠(𝑒𝑑𝑔𝑒 = 𝐸𝑑𝑔𝑒𝑇𝑦𝑝𝑒 (𝑠)) 表示查询𝑡的直接后继者可以通过UDG上的特定EdgeType(s)的边到达。为了后续的优化,缓存每个目标的结果文件集。

算法2显示了如何检测一个目标的所有MD,将其构建过程中访问的文件集($D_t$)与可用的
文件集($S_t$)。$D_t$和$S_t$中的所有文件都是该目标的MDs。
检测依赖冗余(RD)
为了判断𝑝是否是目标𝑡的RD,把𝑝从声明的依赖关系中移除,并检查剩余图中的声明的依赖关系是否仍然覆盖构建𝑡时的相同实际依赖关系。算法3展示了检测的细节。由于一个目标的不同直接依赖的可用文件节点可能会重叠。可以使用一个映射𝑀来记录每个文件节点的直接依赖关系数量。第9行到第12行通过检查移除一个依赖关系是否会减少中的元素数量来进行RD检测。

总结
作者在本文中,讨论了现有的构建错误的检测方法,认为现有的方法并没有很好地利用静态和动态依赖性信息。因此提出了一种基于统一依赖关系图(Unified Dependency Graph ,UDG)的遍历的方法来检测依赖错误(构造UDG后,对于每个构建目标,通过简单的图遍历,既能推断隐式声明的依赖关系,又计算在运行时发生的实际依赖关系,这两个遍历结果的差异意味着依赖关系潜在的不一致性,从而检测出依赖缺失和依赖冗余这两类主要的构建时依赖错误),并且实现了工具VERIBUILD,进行了实验评估。文中的实验结果表明,该方法不仅高效而且不会损失精度。
体会
这篇论文巧妙地运用图论的知识解决软件测试的问题,把软件系统中复杂、难以直观了解的部件依赖关系得抽象成了有向无环图,首先直观得展示出各个文件的输入输出、引用被引用等关系,然后给出了三个算法,通过对同一个图的不同的遍历方式,得到的不同遍历结果,比较差异就能得出依赖关系的不一致,从而检测出依赖错误。实验证明,这种方法非常有效,并且作者将其工具化之后,检测过程也变得十分简捷。
这启示我们,在做科研、在解决复杂的领域内问题时,不妨将视野放长、放宽。放长视野,可以从领域内前人的工作中总结经验教训、吸收优秀的成果等;放宽视野,可以在跨领域的方向得到灵感和启发,它山之石可以攻玉。

