
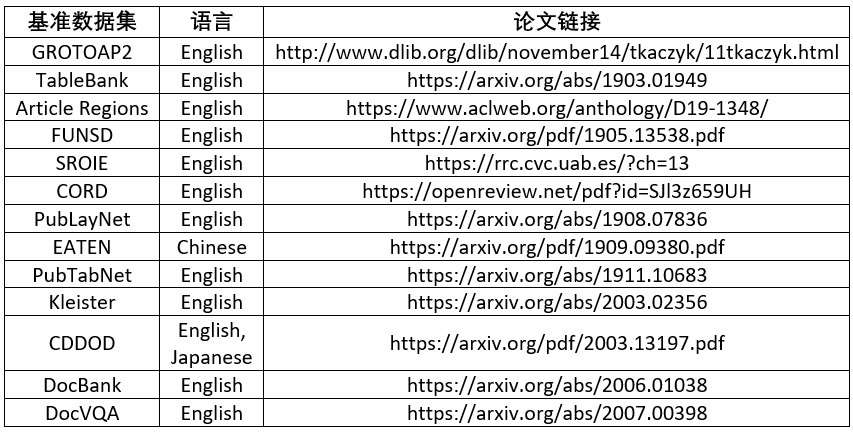
【DOCAI】文档智能领域13个基准数据集的简单介绍
GROTOAP2
GROTOAP2 — The Methodology of Creating a Large Ground Truth Dataset of Scientific Articles
TableBank
TableBank: A Benchmark Dataset for Table Detection and Recognition
TableBank是一个表格检测与识别的数据集,基于公开的、大规模的Word文档和LaTex文档,通过弱监督方法创建而来。与传统的弱监督训练集不同,TableBank不仅数据质量高,而且数据规模比之前的人工标记的表格分析数据集大几个数量级,其表格数据量达到了41.7万。
Table总共包含417,234个高质量标记的表格以及它们在各个领域中的原始文档。具体数据内容如下:
| Task | Word | Latex | Word+Latex |
|---|---|---|---|
| Table detection | 163417 | 253817 | 417234 |
| Table Structure recognition | 56866 | 88597 | 145463 |
Article Regions
Visual Detection with Context for Document Layout Analysis - ACL Anthology
Article Regions数据集用于文本版面分析任务,包含822个文档样本,注释了9个区域类(标题、作者、摘要、正文、图、图标题、表、表标题和参考文献)。标注采用目标检测格式,评价指标为mean average precision(mAP)。
FUNSD
FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents
该数据集在用于FUNSD(有噪声的扫描文档)上进行表单理解。
这里的表单理解是指对表单中的文本内容进行抽取并生成结构化数据。
数据集中包含199个真实的、完全标注的扫描文档表单,每个语义实体包括唯一标识符、标签(即问题、答案、标题或其他)、边界框、与其他实体的链接列表和单词列表。
可用于文本检测、光学字符识别、空间布局分析以及实体标记、链接等任务。
SROIE
该数据集用于票据理解任务,包含626条用于训练的收据样本和347条用于测试的收据。每个收据被整理为带有边框的文本行列表。每个收据都标有四种类型的实体,分别是{公司,日期,地址,总数}。评估指标是实体识别结果的F1 score。
CORD
CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
GitHub - clovaai/cord: CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
该数据集用于票据理解任务,包含1000个收据,每个收据一张照片和一份OCR结果。
PubLayNet
PubLayNet: largest dataset ever for document layout analysis (arxiv.org)
PubLayNet是文档图像版面分析的大型数据集,其布局用多边形边框分割标注。文档的来源是PubMed Central Open Access子集(商业用途集合)。通过匹配PubMed Central Open Access子集中的文章的PDF格式和XML格式,自动生成注释。
PubLayNet包含超过36万个文档图像,其中注释了典型的文档布局元素。
EATEN
EATEN: Entity-aware Attention for Single Shot Visual Text Extraction (arxiv.org)
该数据集用于票据理解任务,包含火车票、护照以及名片三类的不同质量的照片或者扫描图片,最关键的都是中文的!!!
详细内容如下:
| scenes | number | size | Google Drive link |
|---|---|---|---|
| train ticket | 300k synth + 1.9 real | 13G | dataset_trainticket.tar |
| passport | 100k synth | 5.8G | dataset_passport.tar |
| business card | 200k synth | 19G | dataset_business.tar.0 dataset_business.tar.1 dataset_business.tar.2 dataset_business.tar.3 |
PubTabNet
Image-based table recognition: data, model, and evaluation (arxiv.org)
PubTabNet是IBM公司公布的基于图像的表格识别数据集。
其包含了568k+表格图片,其标注数据是HTML的表格结构,下载压缩包磁盘存储大小10G+。
该数据集的表格都是PDF截图,清晰度不是很高.
Kleister
这是一个复杂长文档数据集,用于复杂布局长文档理解任务。提供了254篇合同文档数据,其特点是页面布局复杂且内容较长。预定义了四类关键信息实体可以抽取。
CDDOD
Cross-Domain Document Object Detection: Benchmark Suite and Method
该数据集用于文档图像目标检测任务。

DocBank
DocBank: A Benchmark Dataset for Document Layout Analysis (arxiv.org)
一个文档基准数据集,其中包含了50万文档页面以及用于文档布局分析的细粒度 Token 级标注。与常规的人工标注数据集不同,微软亚洲研究院的方法以简单有效的方式利用弱监督的方法获得了高质量标注。DocBank数据集是文档布局标注数据集 TableBank的扩展,基于互联网上大量的数字化文档进行开发而来。
它包含500K的文档样本和12个区域类(摘要,作者,标题,方程,图,页脚,列表,段落,参考,节,表和标题)。它提供token级别的注释,并使用F1分数作为官方评估指标。同时提供了对象检测标注,支持对象检测方法
DocVQA
[2007.00398] DocVQA: A Dataset for VQA on Document Images (arxiv.org)
这个数据集用于文档图像数据问答任务。该数据集共包含超过一万页文档上的五万组问答对。包含12000页文档,50000个问题,数据集被组织成三元组<页面图像、问题、答案>。