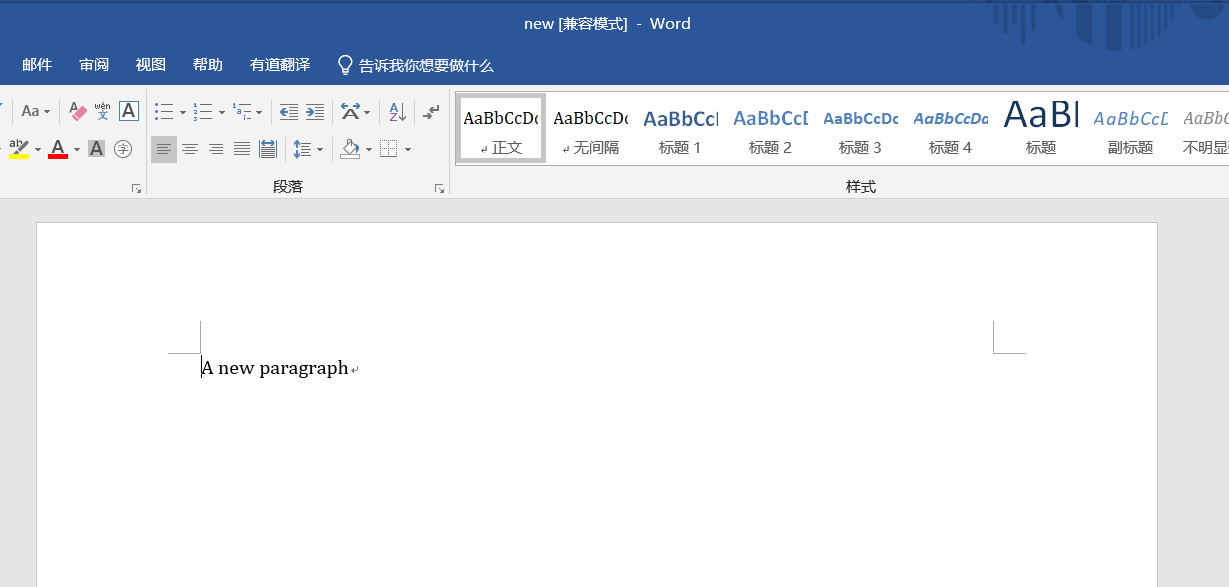
from docx import Document document = Document() p = document.add_paragraph('A new paragraph') # 增加一个段落 path = r'D:\new.docx'# 设置保存路径和文件名 document.save(path) # 保存文档
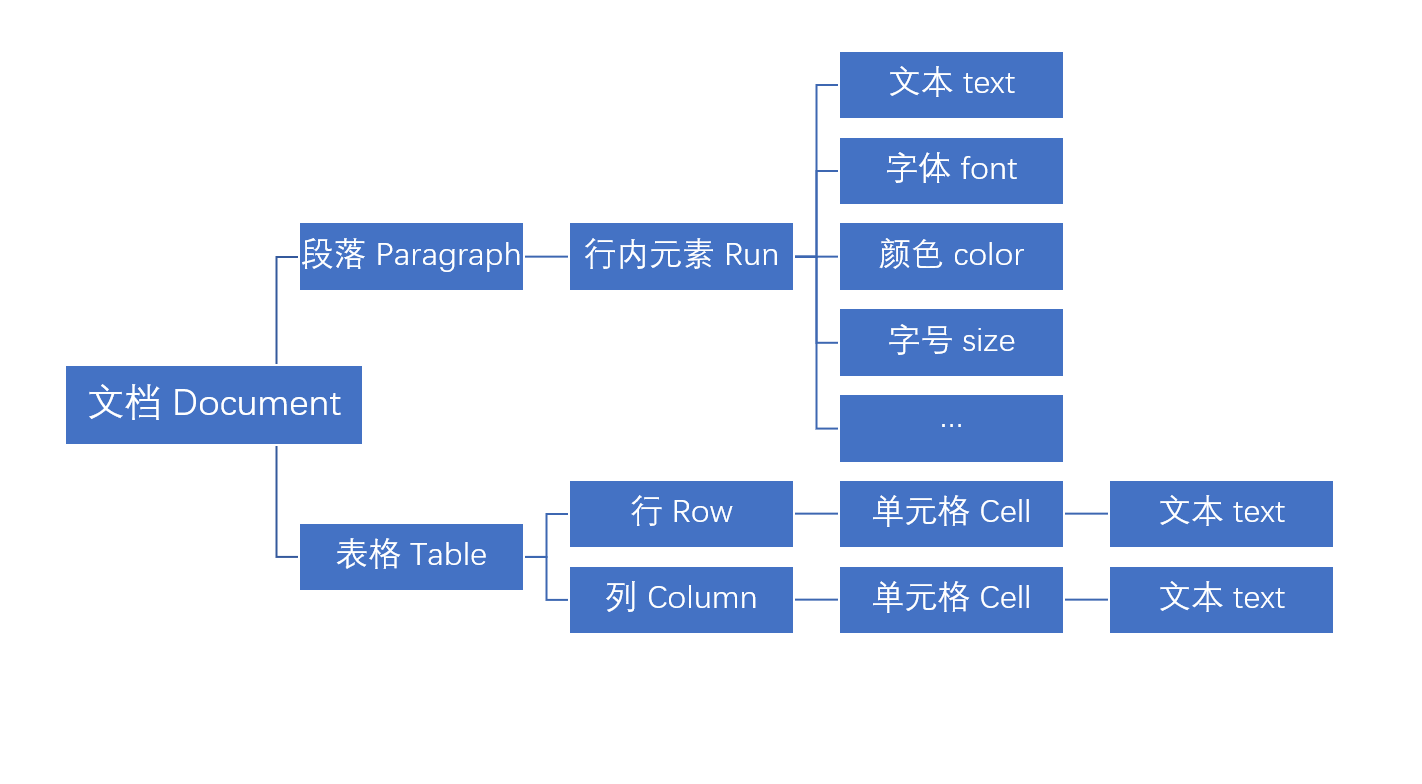
从原文件创建文档对象
1 2 3
from docx import Document path = r'D:\test.docx'Python document = Document(path)
读取段落并输出
1 2
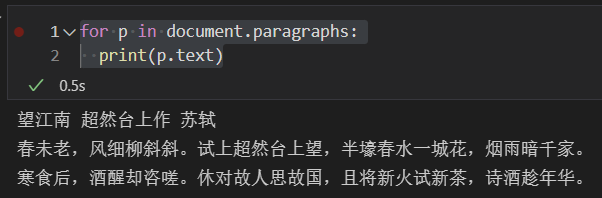
for p in document.paragraphs: print(p.text)
读取表格并输出
需要注意的是,合并的单元格会被拆分并且对内容进行自动填充,所以会有重复内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
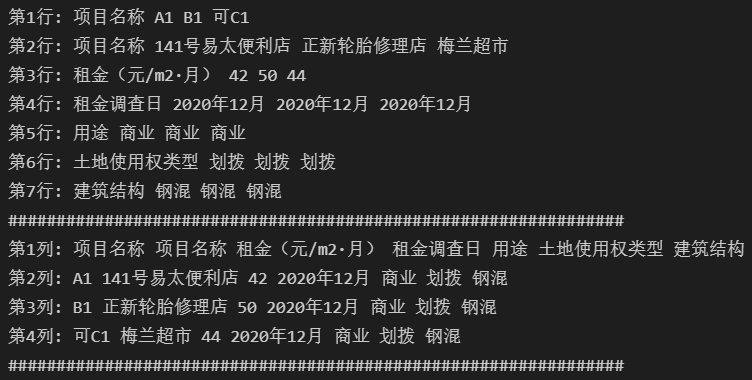
for table in document.tables: i = 1 for row in table.rows: print('第%d行:'%i, end=" ") i += 1 for cell in row.cells: print(cell.text, end=" ") print() print('#'*64) j = 1 for col in table.columns: print('第%d列:'%j, end=" ") j += 1 for cell in col.cells: print(cell.text, end=" ") print() print('#'*64)
defgetTables(doc):# 获取doc中的表格,以矩阵形式返回 tables = [] for table in doc.tables: tb = [] for row in table.rows: t_row = [] for cell in row.cells: t_row.append(cell.text.replace(' ', '')) tb.append(t_row) tables.append(tb) return tables
defprintTable(table): print('[') for row in table: print(row) print(']')
t_cnt = 0 for table in getTables(document): t_cnt += 1 print('表%d:'%t_cnt) printTable(table)